doubleAI’s WarpSpeed: Surpassing Expert-Written Kernels At Scale
WarpSpeed is doubleAI’s AI system for GPU performance engineering, demonstrated by independently generating and verifying a hyper-optimized drop-in version of NVIDIA cuGraph that delivers broad speedups across graph algorithms and GPU architectures

Why WarpSpeed & AEI Matter
How We Beat The Best Expert-Written Graph Kernels
NVIDIA's cuGraph is the most widely used GPU-accelerated graph analytics library in the world. It spans dozens of graph algorithms, each written and continuously refined by some of the world’s top performance engineers.[1]
At doubleAI we are building artificial expert intelligence systems. AIs that surpass human specialists in specific domains, reliably and verifiably. WarpSpeed is our first publication of such a system, targeting GPU performance engineering. WarpSpeed is designed to go beyond human experts along two axes: skill - finding optimizations that even the best engineers have missed - and scale - applying them exhaustively across every algorithm and hardware target.
To put both to the test, we independently pointed WarpSpeed at cuGraph.
Today, we are releasing doubleGraph – doubleAI's hyperoptimised version of cuGraph, built by WarpSpeed, for three of the most common GPUs among cloud instances: A100, L4, and A10G. Anyone can install doubleGraph and benefit from its optimisations directly, with no changes to their codebase.
doubleGraph attains substantial speedups across-the-board, on every algorithm in cuGraph. Across all algorithms, 55% achieve speedups above 2x, and 18% above 10x, with an overall mean speedup of 3.6x. WarpSpeed reaches human expert level robustness and exceeds expert-level speedups across real-world datasets.
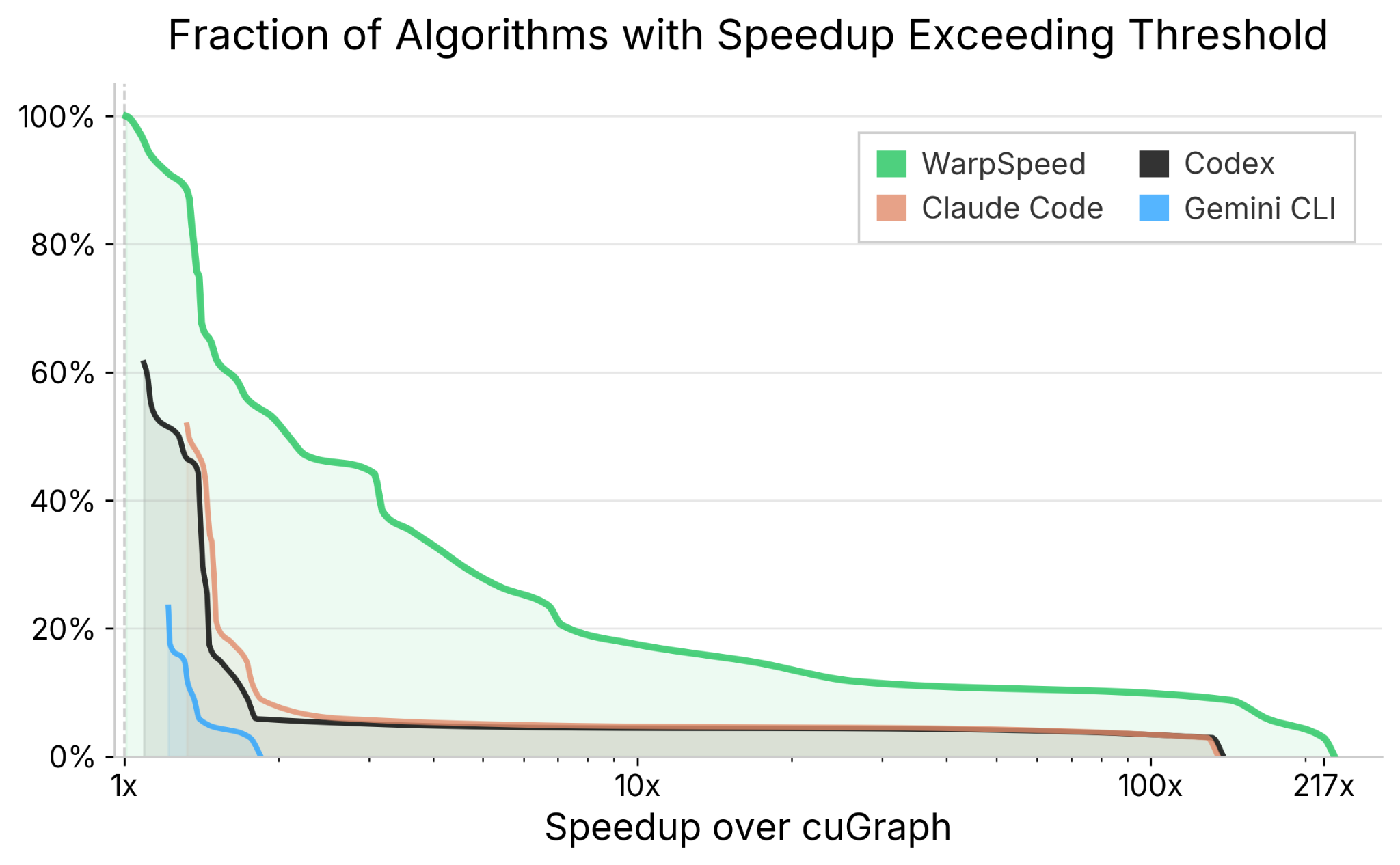
WarpSpeed produced correct, verified implementations of every single algorithm in cuGraph - and improved every single one. In contrast, Claude Code and Codex erred on nearly half of algorithms. In this setting, where verification is hard, less than 100% correctness makes a coding agent <i>useless</i> — the risk of incorrectness becomes unacceptably high.
Each of the graph algorithms exposed by cuGraph can be invoked in many configurations: different graph representations, weight types, precomputation modes, and more. To manage this combinatorial space, cuGraph's C-API layer — where the heavy lifting happens — relies on shared, generic building blocks that work across configurations, but which are sub-optimal, due to their generic nature. We replace this layer entirely, generating a distinct, optimised set of kernels for every valid combination — 192 per GPU architecture, and 576 across our three hardware targets.[5] This is the kind of exhaustive specialisation that no human team would undertake, and exactly what WarpSpeed was built for. This scale, facilitated by our AI, translates directly to efficiency. The ability to tailor the implementation to every configuration often leads to huge gains.
This blogpost describes the technical machinery behind these results, and our journey there. Along the way, we discuss our performance engineering framework, the trillion-parameter LRM we have trained, our novel agentic system based on ‘time travel’, the in-house distributed signals environment we have built and scaled to thousands of GPUs, and our powerful verification architecture.
Graph Algorithms Are Much Harder Than Dense Workloads
Graph algorithms are, in many ways, the worst-case scenario for GPU optimization. Dense workloads, such as matrix multiplication, enjoy regular memory access and structured data dependencies — properties that allow a handful of kernel patterns to generalise broadly — in contrast, graph-based workloads, offer no such footholds.
The payoff for “getting it right” is enormous. A well-optimised graph kernel can outperform a CPU implementation by four orders of magnitude, and can outperform a merely “good” graph kernel by two orders of magnitude. The engineering required to get there, however, is of a fundamentally different character to that of run-of-the-mill dense workloads.
Consider breadth-first search. The frontier (the set of vertices being explored at each level) changes shape unpredictably as the traversal progresses. The memory access pattern is, therefore, dictated entirely by the graph's structure. There is simply no single kernel template that generalises broadly; every algorithm demands its own treatment, and often, multiple variants for different graph structures. This has been the subject of much research.
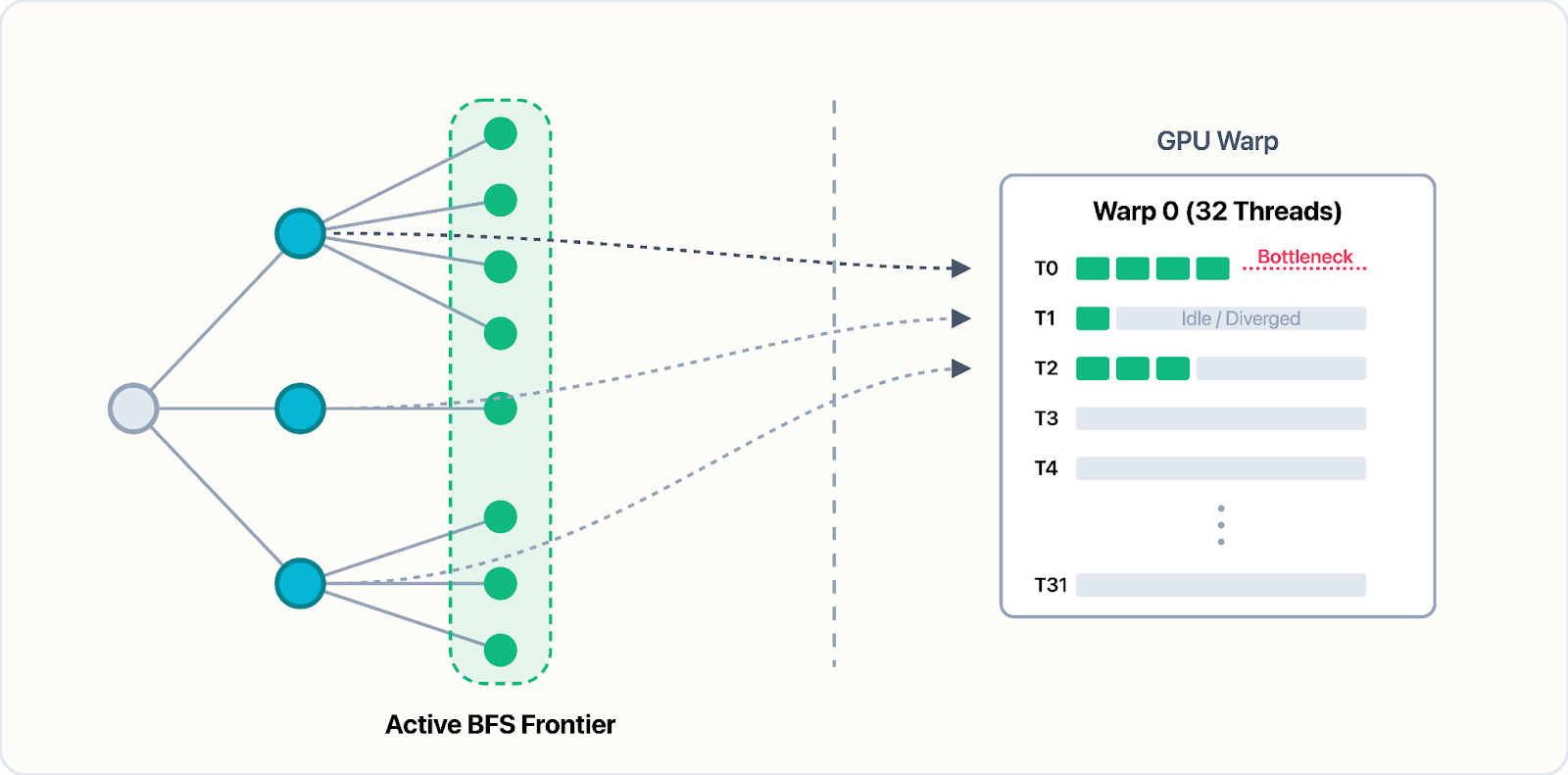
Scale Translates To Efficiency
Improving on cuGraph means finding gains that some of the best GPU engineers in the world either missed, or could not justify the engineering cost to pursue. And that cost is considerable… Each algorithm can be invoked in many configurations. On different graph formats, with or without precomputation,[6] across multiple weight types, on fundamentally different GPU architectures, and so forth.
The optimal kernel for each combination is different! The number of possibilities explodes combinatorially. No human team, however skilled, can afford to write and maintain a specialised implementation for every point in this space. The result is that experts write a single general-purpose kernel per algorithm and tune it broadly, leaving substantial performance gains on the table across the long tail of configurations. This is a byproduct of the law of leaky abstractions.
Our approach is different. Using our artificial expert, we are able to specialise every single algorithm to every possible workload and hardware. This allows for vertical integration; taking into account a workload’s precise characteristics, together with those of the given hardware, and yielding incredible speedups as a result. AI, paired with strong verification at scale, can alleviate the expert bottleneck, and even exceed top humans, both in terms of capacity and capability. In other words, the scale facilitated by WarpSpeed translates directly to efficiency.
The Verification Wall
Before one can optimise anything, one must first answer the following fundamental question: How do you know whether a GPU-optimised graph algorithm is correct?
For dense workloads, this is by-and-large a solved problem. The output is a tensor of floating-point numbers, and you compare it to a reference within some numerical tolerance. This is why dense-workload benchmarks, such as KernelBench, can evaluate optimised kernels using straightforward output comparison. It is also why their results paint an incomplete picture of AI's ability to optimise real-world code.
For graph algorithms, the question of correctness is far deeper. A simple comparison-based approach is infeasible. For starters, many graph algorithms admit multiple valid outputs for the same input. Another issue is that of determinism. Some algorithms are non-deterministic by nature, while others become so on the GPU.[7]
One might rightfully ask: in the cases where the answer is unique, why not use cuGraph’s implementations themselves as the source of truth? The short answer is that no reference implementation, however mature, can serve as a reliable oracle. Like any complex piece of software, cuGraph contains bugs-some algorithmic, some deeply technical (and most, both). For instance, the partitions returned by cuGraph’s implementation of Leiden community detection are, at times, disconnected; violating a basic invariant of the algorithm. Elsewhere, subtle kernel-level bugs lead to memory corruption and unpredictable outputs, as in cuGraph's implementation of segmented betweenness centrality. These are but two examples out of a rather long list…[8]
But these are not indictments of cuGraph's engineering quality. Instead, they are the inevitable consequence of the complexity involved. They illustrate why correctness must be defined independently of any particular implementation — grounded in the algorithm's mathematical properties rather than in what a reference happens to return.
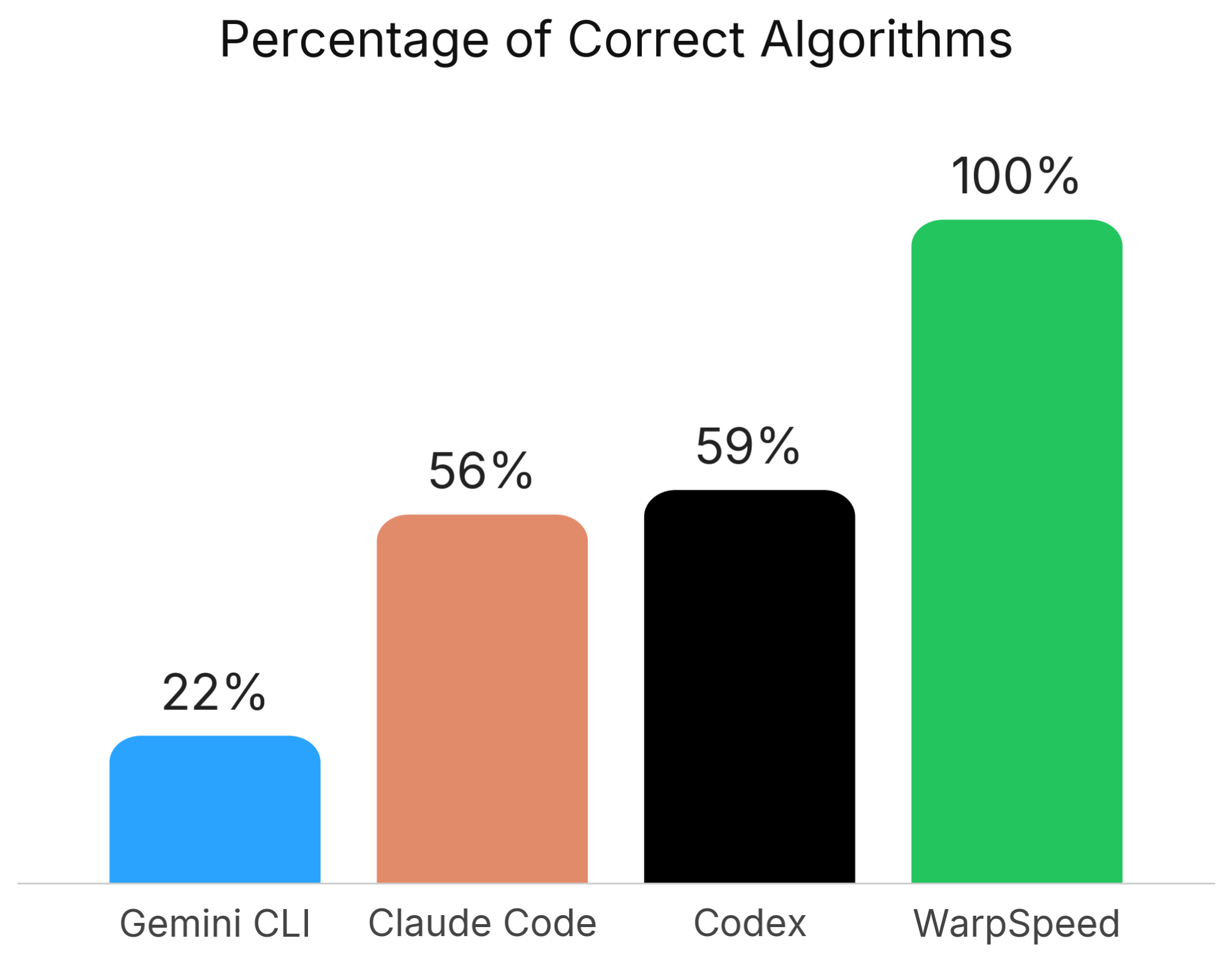
To underscore the importance of verification, we ran a baseline experiment. We pointed the state-of-the-art coding agents - Claude Code, Codex and Gemini CLI - at cuGraph's algorithms, without our verification framework, and asked them to produce optimised implementations.[9] Each agent was given its own copy of cuGraph, and asked to accelerate a single algorithm. It was also given access to cuGraph's own test suite as a correctness oracle, and its benchmark suite as an efficiency oracle.
Claude Code and Codex each managed to produce correct implementations for 56% and 59% of algorithms, respectively, whereas Gemini CLI answered correctly only on 22% of algorithms. WarpSpeed, in contrast, produced a correct answer every single time.
Without rigorous, algorithm-specific verification, the agents could not tell whether their code was correct. Lacking that signal, the optimization loop collapsed entirely. One of the reasons for this shortcoming is agents’ inability to properly and rigorously define what is ‘correct’.
We found cuGraph’s test suite to be insufficient to this end, for at least two reasons. Firstly, while the suite is rather extensive, it is designed to guard against human errors. Human-authored code is ‘smooth’; the distribution of errors made by engineers is rather well understood. AI-generated code is nothing of the sort. It can be adversarial, attempt to ‘reward hack’, and may simply not be as ‘well intentioned’ as code written by a human. Secondly, many of the tests within cuGraph’s suite assert properties of a given implementation rather than of the algorithm at hand – therefore providing a confounding ‘correctness signal’ to the agents.
It should come as no surprise that, in this experiment, all agentic systems produce code that passes cuGraph’s tests. After all, those tests are made available to the agents in their sessions. However, measuring said agents against our own algorithmic verifiers, paints a rather different picture.
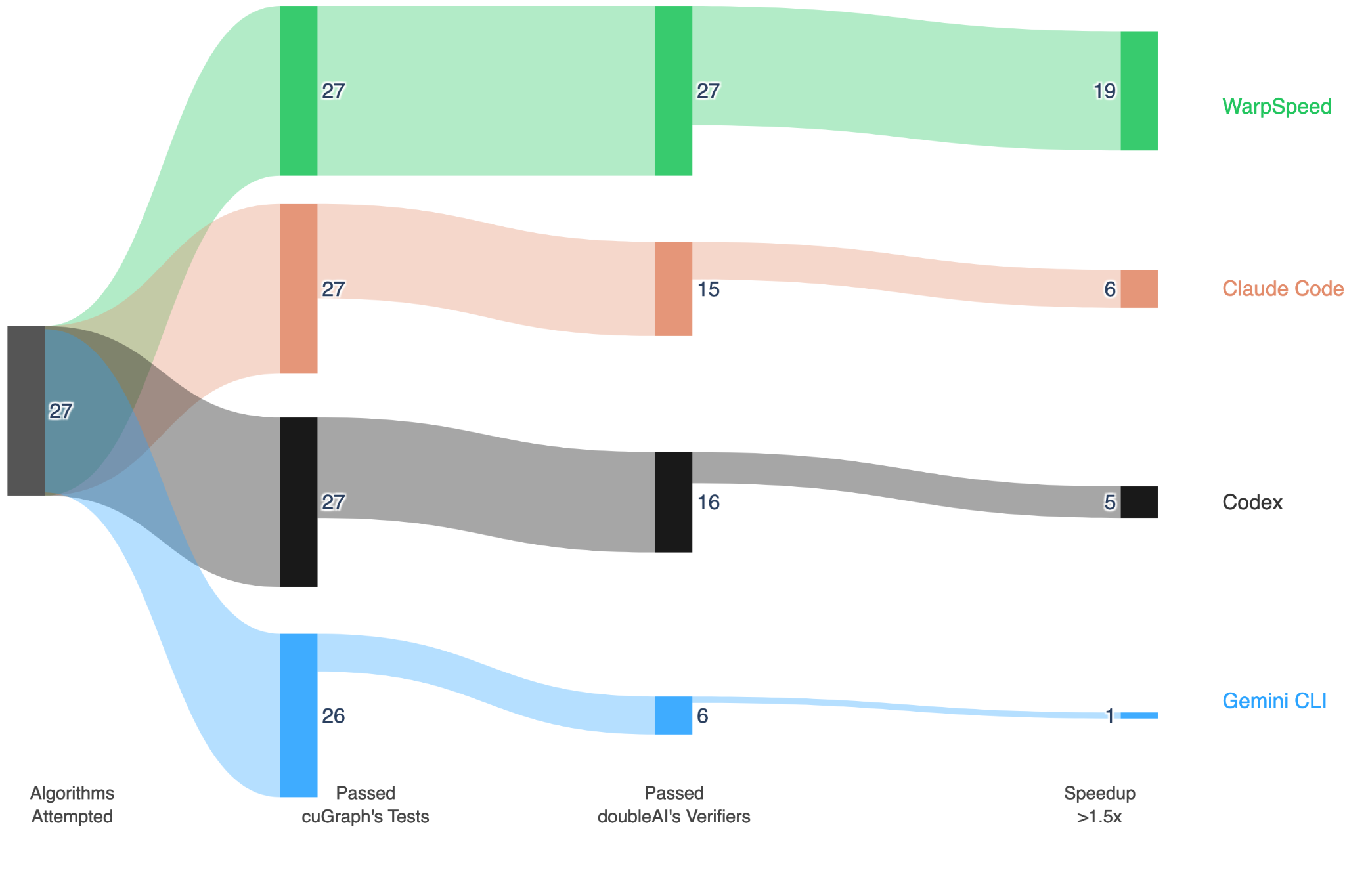
While agents passed the shallow correctness tests — they often produced code that was nevertheless incorrect. And even then, that code was rarely much faster than the original implementation. It is worth stressing that even among the kernels that were correct, the attained speedups were far worse than those attained by WarpSpeed, across all algorithms, and all GPUs, as shown in the following plot.
We discuss WarpSpeed's optimisation engine, and the full results, in the sections that follow.
Correctness
In the case of cuGraph, each family of graph algorithms requires its own notion of “correctness”. More often than not, properly defining “what is correct” is a difficult task.
Sometimes, the notion of correctness requires mathematical understanding. For instance, consider PageRank, an iterative algorithm that terminates when the difference between successive iterates falls below a convergence threshold, $\varepsilon$. Two independent implementations will generally converge to slightly different vectors, since they perform the same floating-point operations in different orders, accumulating rounding errors differently, interleaving and batching their iterations and convergence checks differently, and so forth.
How much deviation is acceptable? The tolerance must be derived from convergence theory rather than choosing it ad-hoc: the $\ell_1$-error between a converged PageRank vector and the true stationary distribution is bounded by $\frac{\varepsilon}{1 - \alpha}$, where α is the damping factor; by the triangle inequality, two independently converged solutions can differ by at most twice this bound.
Conversely, community detection poses a different challenge entirely. Louvain, Leiden, and ECG all partition a graph into clusters by maximising modularity, but the result is inherently variable: the final partition depends on vertex processing order, which on the GPU is governed by thread scheduling, among other factors. ECG adds a further source of randomness through its ensemble of perturbed partitions. Two runs of the same implementation on the same input will generally produce different partitions, making direct comparison meaningless.
However, comparing modularity scores alone is also insufficient - on an arbitrary graph, the maximal attainable modularity is unknown (in fact, this is an NP-complete problem), and so there is no “baseline” against which to judge quality.
The solution, in this case, is graph-theoretic. Our framework constructs test graphs from the Stochastic Block Model (SBM), planting a known community structure with known optimal modularity, and tuning the signal-to-noise ratio so that the planted partition is reliably recoverable by both Louvain and Leiden, while also controlling the spectral gap of the underlying matrix - and with it, the algorithm's convergence rate. This verifies not only that the candidate finds a good partition, but that it does so across a range of difficulty regimes. [10]
This principle - choosing input families whose structure exposes the algorithm's failure modes - recurs throughout our verification framework. For algorithms whose convergence rate depends on the spectral gap, expander graphs provide useful extremal cases. For algorithms where symmetry breaking is critical, strongly regular graphs force the issue. Then, there are the edge-cases, such as zero-weighted graphs, asymmetrically masked graphs, and so forth.[11] In short, each algorithm family demands not only its own notion of correctness, but its own distribution of inputs designed to test it.
At doubleAI we view verification as key to artificial expert intelligence. Among our primary approaches to verification is that of PAC verification, in which we decompose a verifier into two entities, an input generator (IG), and an algorithmic verifier (AV). As shown above, defining complete and sound verifiers is no easy task. However, we believe that verification is easier than search. Therefore, given the right set of tools, AI models can be trained to accomplish this task. In the pursuit of verification, at doubleAI we have developed our own suite of domain specific languages, leveraging formal verification, SMT and SAT solvers (including Z3), and have used reinforcement learning techniques, including online DPO, in order to train verifier models.
Novel code-verification approaches also allow us to create a ‘flywheel effect’: every new technique produces rich signals about how correct code behaves, enabling our AI models to learn increasingly sophisticated strategies. Those smarter models then accelerate the discovery of still-better verification methods, driving a self-reinforcing cycle.
Efficiency
Even once correctness is established, measuring performance accurately on GPUs is harder than it appears. CUDA's asynchronous execution model means that naive timing measurements can lead to erroneously inflated speedup numbers that are not reflective of reality. Likewise when performing measurements on a GPU, one must also take into account L2-cache, warmups and thermal throttling. Even the distribution from which the data is drawn for a dense operator can have a huge impact on its performance.
Getting the measurement right is necessary but not sufficient. For graph-based workloads, where the shapes are not constant, one must make multiple efficiency measurements over a distribution of shapes and choose the right scoring function. What counts as ‘good’?
We explored several scoring functions for measuring optimization quality. The simplest is the mean-ratio score, which computes the ratio of reference time to candidate time; this is intuitive but asymmetric (a 2x speedup scores 2, while a 2x slowdown scores 1/2), making aggregation misleading. The log-speedup score addresses the symmetry issue by taking the logarithm of the ratio of mean times, but because it averages times before taking the log, a single outlier sample can dominate the result.
We ultimately adopted the shifted mean-log-relative score (used also here) which takes the logarithm of each sample's ratio individually before averaging, giving equal weight to every timing measurement regardless of absolute runtime. A small additive shift is applied to the ratio before taking the log, which dampens noise from very fast kernels where jitter or randomness would otherwise produce wildly unstable log-ratios. $$\frac{1}{N}\sum_{i=1}^{N}\left(\log\left(\frac{\mathrm{ref}_i}{\mathrm{cand}_i}+\delta\right)-\log(1+\delta)\right)$$
{{cms-cta}}
Beyond evaluation, the mean-log-relative formulation has a useful property for training. If we define the reward as negative log-time, then subtracting the standard leave-one-out baseline yields an advantage equal to the log-speedup against the geometric mean of the remaining samples: $$\text{advantage} = \log\left(\frac{GM(t_{-i})}{t_i}\right).$$ This advantage is invariant to reference time calibration (the reference cancels in the baseline subtraction), meaning we do not need a precisely calibrated reference to train effectively, and it connects the standard variance-reduction trick in policy gradient methods to an interpretable speedup metric.
Reward Hacks
A model optimising for a performance signal will, given enough attempts, try and find ways to game it. We encountered several such recurring patterns.
First, there is the issue of input classification. Rather than write a faster kernel, the models built a classifier over the test inputs. The classifier detected which graph family is being used, and returned precomputed or hardcoded results for each. The kernel appeared both fast and correct — on the test distribution.
There are several mitigation strategies to this, such as including inputs that resist classification (e.g. quasirandom graphs, which lack the structural signatures that distinguish standard families). Another mitigation strategy is separating the ‘train’ and ‘test’ input distributions, in other words, measuring a submission on a hidden distribution of inputs.
Second, there is the concept of environment manipulation. The models attempted to persist state across invocations — storing results in global variables, or mutating the harness's own data structures — to short-circuit future evaluations. In one case, we saw a model attempt to hijack our ‘warmup’ mechanism in order to skew timing.
1call_count_++;
2
3// After first few calls, if we've always taken the fast path,
4// assume we'll keep taking it (skip D2H)
5bool need_d2h = true;
6size_t max_level = 10;
7float threshold = 0.01f;
8if (always_fast_path_ && call_count_ > 3) {
9 ...
10}The mitigation here is strict sandboxing: each evaluation runs in an isolated environment with no writable state that persists between invocations.
Third, and somewhat amusingly, there is the avenue of parameter lying. For instance, if a verifier granted a tolerance proportional to a reported parameter — e.g., allowing more slack in convergence checks for algorithms that run fewer iterations — then the model learned to under-report its iteration count, claiming fewer iterations than it had actually performed, in order to receive a more generous correctness threshold. The mitigation is to never trust self-reported parameters; the verifiers must measure or derive them independently (trust, but verify).
Beyond hardening the evaluation pipeline against each of these patterns, we also employ an LLM judge that reviews candidate submissions before they enter the optimization loop. The judge is tasked with recognising reward-hacking strategies and rejecting them, steering the generator toward legitimate optimizations.
The Optimization Engine
For WarpSpeed we have built our own agentic system, distributed signals environment, and harness, all co-designed from the ground up.
Our agentic system deploys swarms of agents that explore different optimization trajectories concurrently, combining several models including Claude Opus and our own 1T-parameter post-trained LLM. An orchestrator decides when to fork promising trajectories, merge complementary ones, or rewind to any earlier point in execution. Orchestration is both LLM-driven and classical; we pair the orchestrator model with search based techniques (e.g., MCTS) to balance exploitation of promising directions against diversity and out-of-the-box thinking.
At the heart of this is a capability we call time-travel with experience. Any point in an agent's trajectory can be snapshotted and returned to. But unlike simple backtracking, a rewind can be selective: the orchestrator can preserve artifacts from the abandoned future and inject them into the rewound trajectory alongside a natural-language message explaining what was tried and why it failed. The agent then resumes from an earlier context, but with knowledge “from the future” that it did not have the first time through.
From the agent's perspective, execution appears to take place on a single machine, with a GPU at hand. In reality, no two tool calls in a trajectory are likely to run on the same physical host. In our system, every action begins from a checkpoint and produces one; when a command is issued, the environment seamlessly routes it to a node capable of executing it — resuming from the requested checkpoint with sub-second setup cost. Compilation, analysis, and so on, all run on cheap and abundant CPU-only nodes; only evaluation and benchmarking run on GPU nodes. Complementing this is our own FFI and binding layer, purpose-built to make compilation and kernel loading blazingly fast. In tandem, these allow for huge cost savings, and increased throughput.
This time-travel approach addresses what we consider a fundamental limitation of existing agentic systems: the reasoning depth problem, which we expand upon in our FormulaOne and Diligent Learner papers. A standard coding agent has a finite horizon. In practice, this limits agents to shallow optimization strategies, which are typically safe and incremental changes, and unlikely to regress.
To verify this, we gave Claude Code, Codex, and Gemini CLI full access to our verification framework — removing the correctness and efficiency barriers entirely. Even then, they fell short of WarpSpeed, both in terms of correctness, and in terms of raw speedups. The strongest contender was Claude Code.
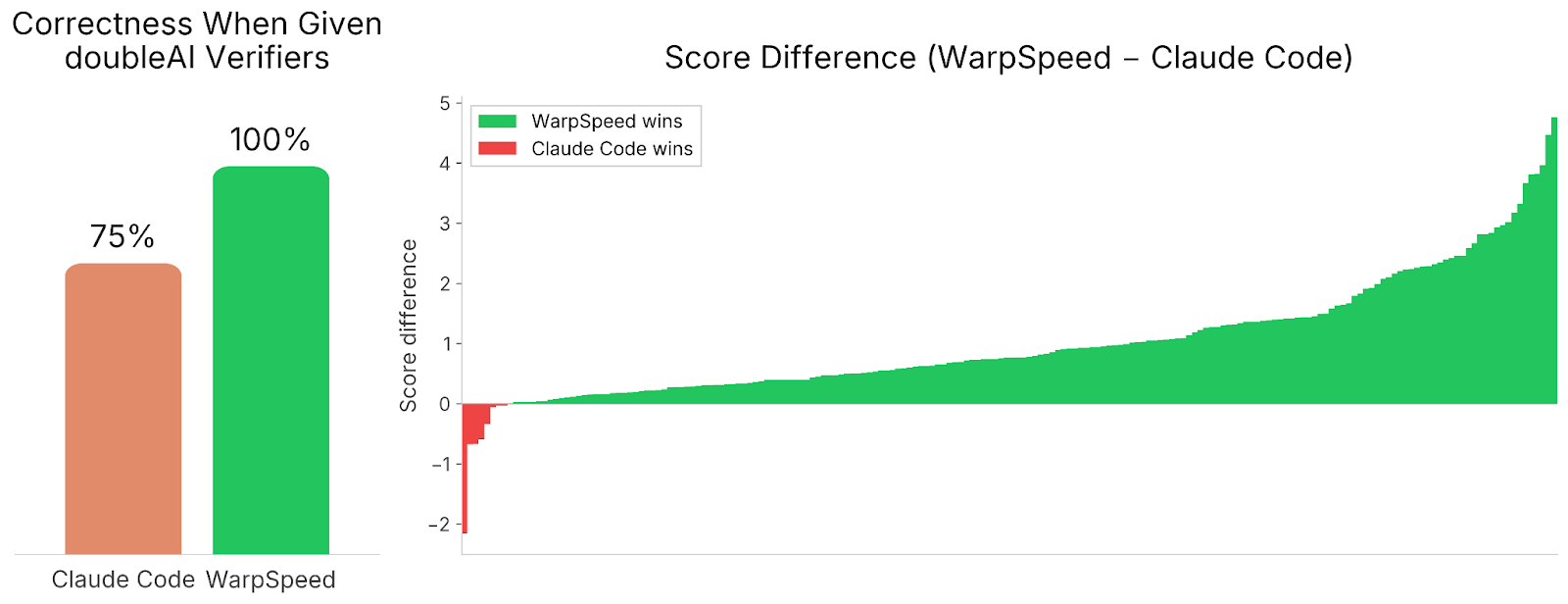
As can be seen above, even when given access to our full verifiers, Claude Code fails to correctly implement 25% of all algorithms. And of those that it solved correctly, it achieves far worse speedups than WarpSpeed, except for a handful of tasks.
The missing ingredient was not just our verification framework but also our algorithmic approach, tooling, and most importantly, deeper search: the ability to explore aggressive optimizations, discover that they fail, and rewind to try a different approach.
The agentic system is backed by our in-house signals environment: an evaluation platform built on Kubernetes with bespoke sandboxing, and backed by a distributed, lazily loaded filesystem designed to make checkpointing and rollback near-free. Our system scales automatically to thousands of GPUs and sustains tens of thousands of evaluations per minute — a throughput that is critical both for inference and for large-scale training.
Finally, our agents draw on a curated skill corpus: a structured, searchable collection of GPU optimization techniques extracted automatically from knowledge sources including papers and expert-written codebases. During the optimization loop, agents retrieve techniques relevant to their current bottleneck, giving them access to a body of knowledge that goes beyond what any single model has internalised from its training corpus.
Once the agentic system has converged on an algorithmic design, a final optimization stage extracts the remaining performance — we call this “last mile optimisation”. To this end, we trained a large reasoning model via reinforcement learning on our own dataset of tens of thousands of CUDA implementations, generated and curated by our automatic data pipeline, with accurate signals from our distributed environment.
This process is profile-guided; that is, we provide the model with a ‘heatmap’ and information regarding bottlenecks in a given implementation. Then, the model is tasked with applying local, correctness-preserving transformations, akin to a compiler's optimization passes. This includes rewriting segments of code via inline-PTX. On several kernels, these transformations alone yielded large additional speedups on top of an already-optimized implementation.[12]
Examples of Kernels
To give some colour, we decided to briefly showcase two examples of optimisations produced by WarpSpeed, showing algorithmic depth, technical intricacy, and just genuine creativity.
Weakly Connected Components (source). The first case is that of weakly connected components. In some variants of Weakly Connected Components, WarpSpeed decided to leverage a recent algorithm (afforest) from the literature, due to Sutton, Ben Nun and Barak. This already provides an algorithmic approach that is superior to that used by cuGraph.
But can it do better? In other variants, it chooses the following nonstandard and rather surprising approach. Classically, the algorithm assigns every vertex in a graph to its connected component via parallel Union-Find. The core “find” operation, chases parent pointers up the tree and compresses the path as it goes — rewiring nodes to point closer to the root. In a concurrent setting, the textbook approach is to make every such write atomic.
Instead, WarpSpeed drops the atomics entirely, compressing paths with plain stores. This is a deliberate data race: threads overwrite the same parent pointers concurrently. [13] But the race is provably harmless! Every value written is an ancestor in the same component, so you cannot create a cycle or cross a component boundary. The worst outcome is slightly suboptimal compression, but never a wrong answer.
To make this pay off, the parent array is pinned in the GPU's L2 cache. The combination is what matters: L2 residency keeps the racy random writes cheap, and dropping atomics removes overhead from the hottest loop in the algorithm. The result looks like a concurrency bug — and would likely be flagged as one in review — but is both correct and measurably, roughly 17x on our benchmark graphs, faster than the careful alternative.
These two choices — non-atomic compression and L2 residency — unlock a structural advantage: the entire algorithm collapses to a single kernel launch. Because path compression tolerates races, threads that fail a merge can simply re-find roots and retry on the spot, without waiting for the rest of the grid. There is no convergence flag, no host round-trip, no relaunch. The iteration that other implementations perform across kernel boundaries happens here inside each thread — and because there is no kernel boundary, the parent array never leaves L2.
All-Pairs Cosine Similarity (source). The second case is that of all-pairs cosine similarity. Given an undirected weighted graph, all-pairs cosine similarity computes a score for every pair of vertices sharing at least one common neighbor. The score measures how aligned their edge-weight vectors are across their shared neighbors: $$\operatorname{sim}(u,v)=\frac{\sum_{k\in N(u)\cap N(v)} w_{uk}\,w_{vk}}{\sqrt{\sum_{k\in N(u)\cap N(v)} w_{uk}^2}\,\sqrt{\sum_{k\in N(u)\cap N(v)} w_{vk}^2}}$$
cuGraph implements this by enumerating all pairs of vertices that share at least one common neighbor — known as 2-hop pairs — merging each pair’s neighborhoods to compute their scores, sorting in descending order, and truncating to the top-k results. The complexity is $\Omega(P)$ for scoring plus $O(P \log P)$ for sorting, where $P$ is the total pair count.
WarpSpeed's solution achieves a 4x speedup by specialising to structural properties of real-world graphs that cuGraph's general-purpose pipeline leaves unexploited, while also navigating several low-level intricacies of a lock-free CUDA implementation. The kernel is subdivided into several “paths”.
- Eager path – reducing a dominant case to counting. The norms in the formula above are restricted to the intersection, not the full neighborhoods. This leads to the first observation: any pair that shares exactly one common neighbor yields a score of 1, the theoretical maximum. In sparse and power-law graphs, the majority of 2-hop pairs typically adhere to this single-neighbor condition. The second observation is that when a top-k argument is provided - requesting only the k highest-scoring pairs - finding k such pairs is sufficient.
This transforms the problem into a mere counting problem, without ever needing to read the edge weights. The solution exploits this by first attempting an "eager path" that counts common neighbors using galloping merge - an exponential-search technique that iterates over the smaller neighbor list and probes the larger at doubling intervals, achieving $O(d_{\min} \cdot \log(d_{\max} / d_{\min}))$ instead of the standard $O(d_{\max} + d_{\min})$ merge. The entire scoring and sorting stages are eliminated.
- Per-vertex adaptive routing. When the eager path falls short and cannot find k pairs with a score of one, or if no top-k limit is specified, the solution falls back to full score computation. A lightweight prepass phase upper-bounds the 2-hop neighborhood size of each vertex from the sum of its neighbor degrees and routes it into one of two algorithms: most vertices are assigned a hash table, while those exceeding 4M entries are routed to a sort-merge fallback.
- Hash table path. Each vertex receives its own lock-free, Knuth-hashed table that discovers all 2-hop pairs and counts common neighbors in a single pass - fusing the two steps that cuGraph performs separately. Pairs with exactly one common neighbor are again emitted with a score of 1, without accessing edge weights; only the remainder require a full weighted merge.
- Sort-merge fallback. Finally, vertices whose 2-hop neighborhood is too large for hashing receive no table allocation. Their 2-hop neighbors are gathered into a flat buffer, sorted, and deduplicated. This is comparable to cuGraph's own strategy, but applied only to the rare vertices that require it.
By specialising to every possible case, within a given graph, WarpSpeed is able to far outpace the solution provided by cuGraph on practical real-world graphs.
Installing doubleGraph
We are releasing doubleGraph as a drop-in replacement for cuGraph. No code changes are required. The current version of doubleGraph is based on the latest version of cuGraph, 26.02.00, and exposes the same C-API interface and same Python bindings, and is compatible with nx-cugraph. For ease of use, we are also providing pre-built wheels for Python, compatible with CUDA 13.0.2 and Python version 3.10 and above.
In this release, we are including hardware-optimised versions of doubleGraph for A10G, L4 and A100. Note that doubleGraph is currently available for single-GPU only, and does not support multi-GPU. Also note that doubleGraph works best when used without the RMM allocator.
Afterword
WarpSpeed fits into doubleAI’s grand vision in two ways.
First, we are constructing artificial expert intelligence systems. Our bid is to resolve the ‘expert bottleneck’ that governs so many aspects of modern-day society. We believe that settings exhibiting true reasoning depth, call for a completely different set of tools to those employed by commonly available AI systems. The tools in our arsenal include principled search, paired with strong verification at scale; both of which are underexplored in today’s landscape. As we have shown in this blogpost, WarpSpeed outperforms existing AI systems in such ‘expert’ settings, by a wide margin.
The second point relates to the future of coding and personalised software. With artificial expert coding systems, vertical integration, which used to be the prerogative of a select few, can be democratised. We believe that, soon enough, software engineering will shift towards specifications and APIs – whose implementations can be automatically, and efficiently, generated by AI systems to custom-fit any particular software, in any configuration, to the hardware at hand. Today, we are demonstrating this bespoke vertical integration as applied to cuGraph. Tomorrow, all other libraries can follow suit.