WarpSpeed approaches Speed of Light on Blackwell
WarpSpeed beats NVIDIA's optimised PyTorch baselines on 90% of SOL-ExecBench's 235 Blackwell kernels, running 2.24x faster on average — after a single day of search.

WarpSpeed approaches Speed of Light on Blackwell
NVIDIA recently released SOL-ExecBench: a benchmark of 235 of the hardest CUDA kernels from real production models, including DeepSeek, Qwen, Gemma, Kimi, and Stable Diffusion.
We ran WarpSpeed on these kernels for a single day. Our system beat the benchmark's optimised kernel baselines on 90% of the problems, running 2.24× faster than those baselines, on average [1]. WarpSpeed topped all four of the benchmark's problem sets, both in terms of the number of problems beating the reference and the average speedup.
For context, Cursor reported the first major results on this benchmark last month, April 2026, with what was then the top score. Cursor's multi-agent system ran for three weeks on the benchmark, and beat the optimised baseline on 63% of problems, reaching an average speedup of 1.38×.
Extremely fast kernels
WarpSpeed is doubleAI's artificial expert intelligence for performance engineering. It designs, implements, verifies, specialises, and tunes hand-crafted kernels for any target hardware, including GPUs and CPUs, often exceeding the performance of expert-written code. The verification framework, learning loop, and reasoning techniques behind it are described in our prior post.
We ran our system on NVIDIA's most recent performance engineering benchmark, SOL-ExecBench, for a single day. On 90% of the problems, WarpSpeed produces a kernel that runs faster than NVIDIA's own optimised PyTorch implementation, running 2.24× faster on average.
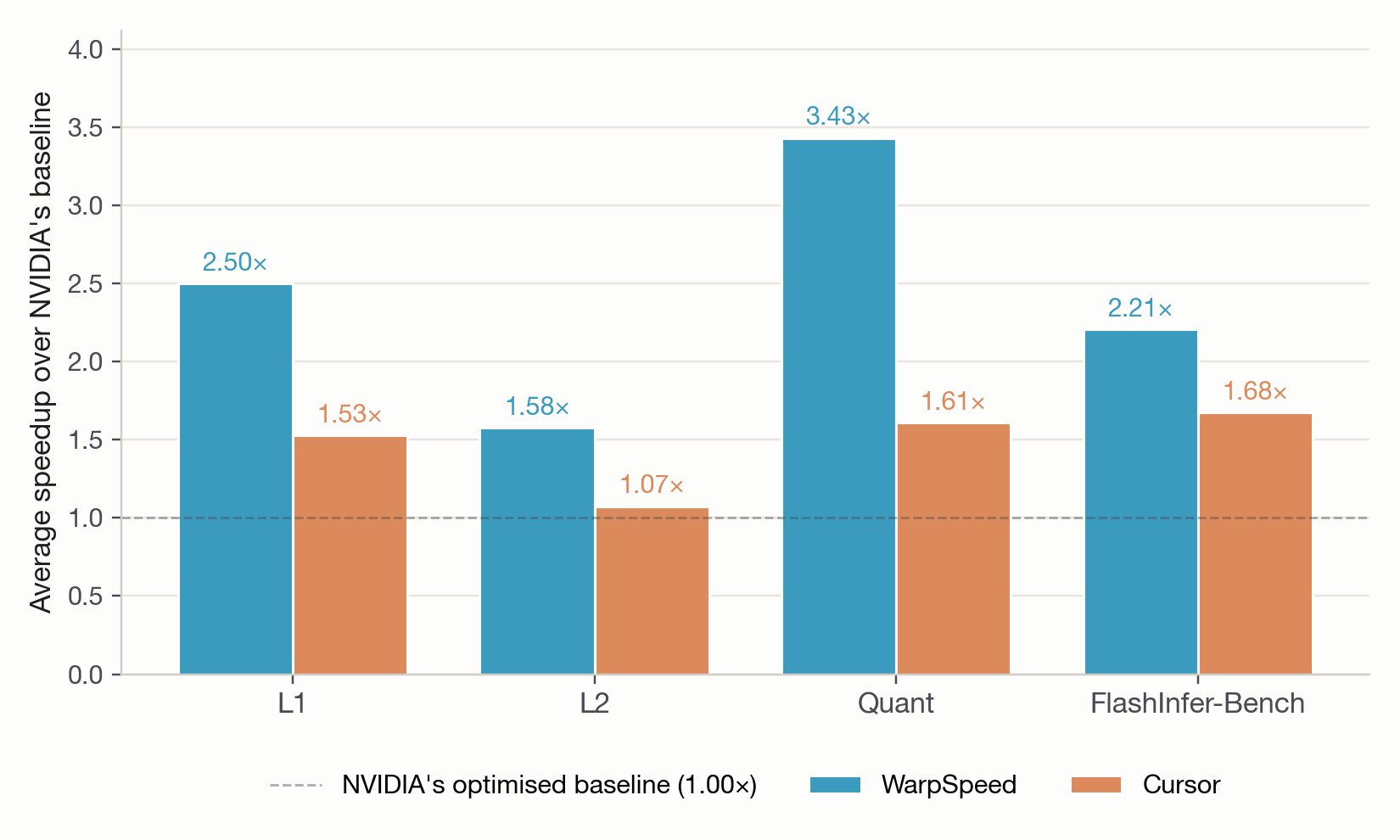
Not all problem sets are equal. Some problems leave more room to optimise than others, and our speedups vary accordingly. Our system did best on the quantisation kernels (NVFP4 and FP8 attention, MoE routing, projection layers), where the right instruction choices and register layout matter enormously. Our fastest among these is an NVFP4 grouped-query attention kernel, the core of NVFP4 inference for any modern transformer; it runs essentially at the speed of light for this workload, and is 14.9× faster than the optimised reference.
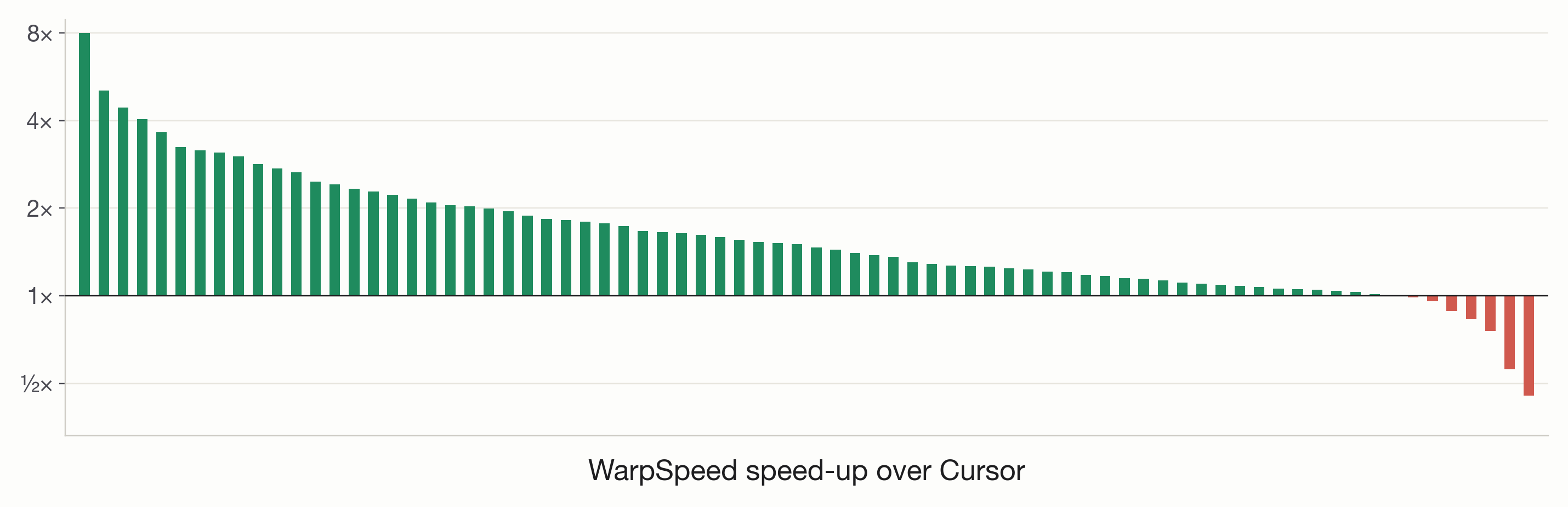
The per-problem picture is also worth taking a look at. WarpSpeed delivers consistent gains across the entire benchmark, producing a meaningfully faster kernel on nearly every problem. A head-to-head comparison against Cursor's agentic swarm illustrates this: our system comes out on top on nearly every problem; the handful of exceptions have small margins, with the widest explained by reward hacks in Cursor's kernels (we cover these in the verification section below).
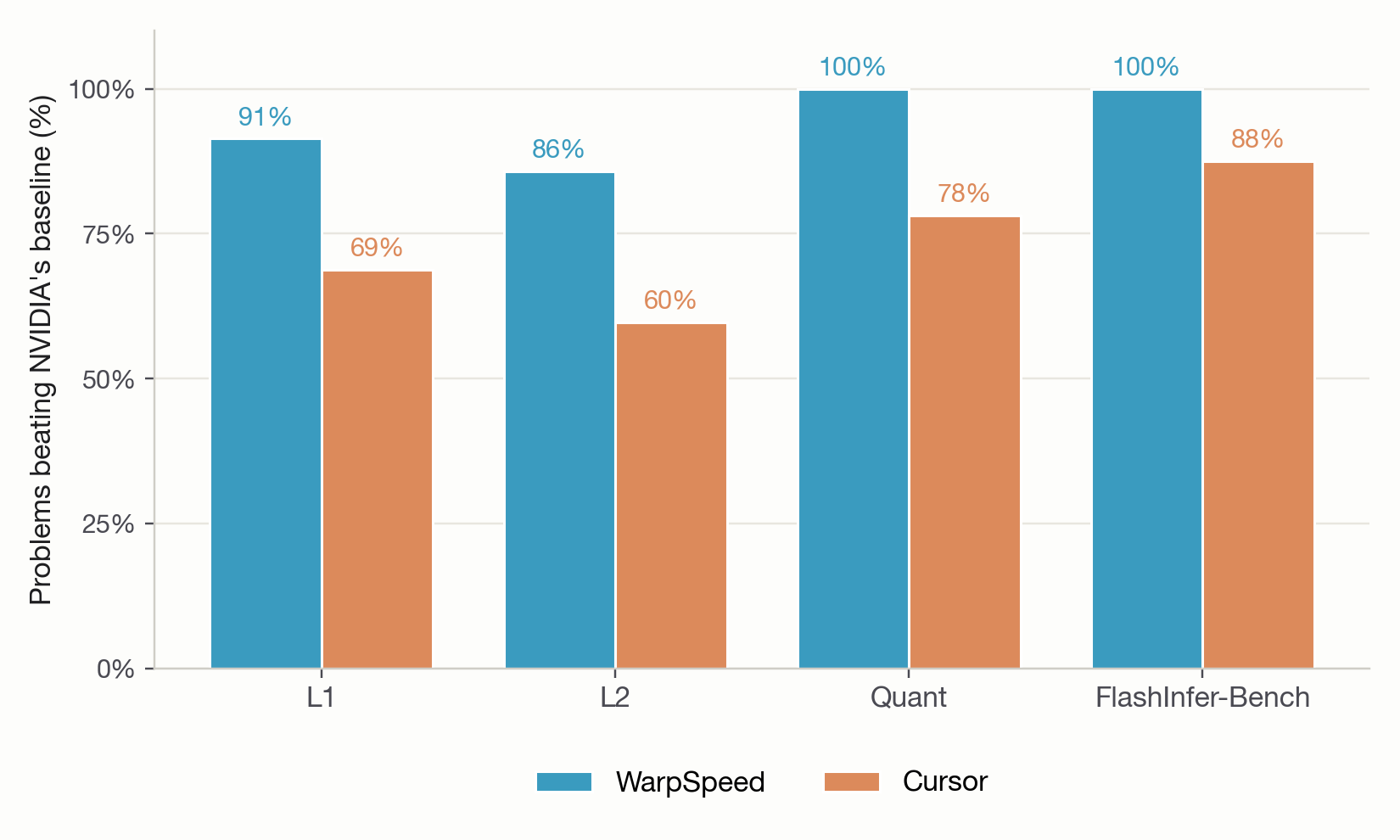
NVIDIA's baselines are not soft targets. The benchmark's 235 problems are split across four sets: atomic single-op kernels lifted from real model architectures (L1), fused multi-op blocks like decoder layers (L2), low-precision FP8 and NVFP4 kernels, the formats powering modern production inference (Quant), and inference primitives traced directly from vLLM and SGLang's serving stacks for Llama-3.1-8B, Qwen3-30B-A3B, and DeepSeek-V3 (FlashInfer-Bench). WarpSpeed beats the optimised PyTorch baseline on the vast majority of problems, in every one of these sets.
Verification is crucial
It's not only about speed.
At doubleAI, we treat verification as paramount. A fast kernel that's quietly wrong is worse than a slow one that's right. For an agentic system that generates kernels at scale, the evaluation harness and the verifier are the only thing telling those two apart.
SOL-ExecBench is a real advance over prior benchmarks. The bulk of its harness engineering goes into hardening the measurement path against reward hacking: every submission runs in an isolated subprocess with SM clocks locked, the L2 cache is flushed between iterations, pointers are shifted to defeat data-address caching, and CUDA events have been replaced with CUPTI activity tracing, which captures kernel timestamps on every stream and closes a common exploit wherein work is hidden on side-streams the timer doesn't see.
The aim of this section is to examine the verifiers of SOL-ExecBench. The intent is not to critique any particular agent's kernels; both Cursor's system and ours optimised against these verifiers. The question we want to ask is: what do these verifiers permit?
The verifiers of ExecBench are straightforward. Each problem ships with a reference, against which the candidate's output is compared element-by-element. A workload passes when 99% of those elements lie within a per-workload tolerance; the remaining 1% can be off by any amount. Inputs are sampled from a fixed RNG seed, so the verifier sees the same bytes on every run. SOL-ExecBench refines this nicely: tolerances are calibrated offline by probing the reference on random inputs. Each of these is a reasonable default. The interesting question is what falls through the cracks when you put them together.
These verifiers are written by human beings, and geared towards defending against human errors. At that task, they are well-designed. The distribution of errors (or hacks) attempted by agents, however, is of an entirely different nature. Human-written verifiers are vulnerable to "reward hacking" and, as a result, may admit incorrect solutions, sometimes harboring bugs that are quite hard to nail down. WarpSpeed has its own verification framework that addresses exactly these failure modes (described in our prior post) [2]. We illustrate these points in detail in the following sections [3].
Passing the verifier and breaking the training
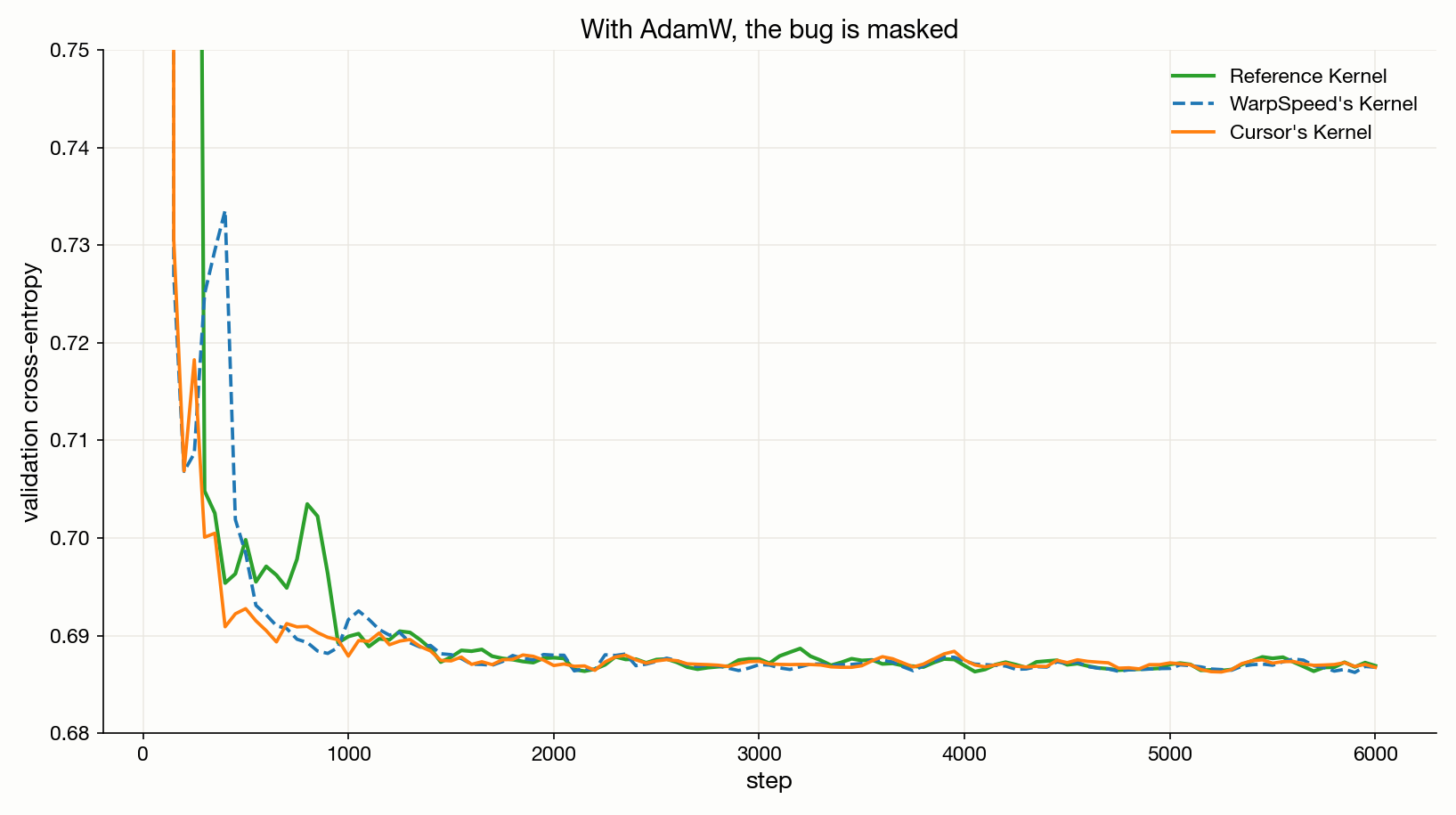
So what does fall through? Let's pick a kernel that passes the benchmark's verifier and use it for its intended purpose. In this case, it is the backward pass through an embedding lookup followed by an RMSNorm, with vocabulary V=65,536 and hidden dimension H=4,096. This is the very last step of any transformer's backward pass, where gradients land back on the embedding parameters.
We trained a small transformer three times on a Zipfian corpus, with plain SGD, identical except for the embedding-gradient kernel: the reference, WarpSpeed's, and Cursor's.
The result? One kernel's training loss diverges and never catches back up. [4]
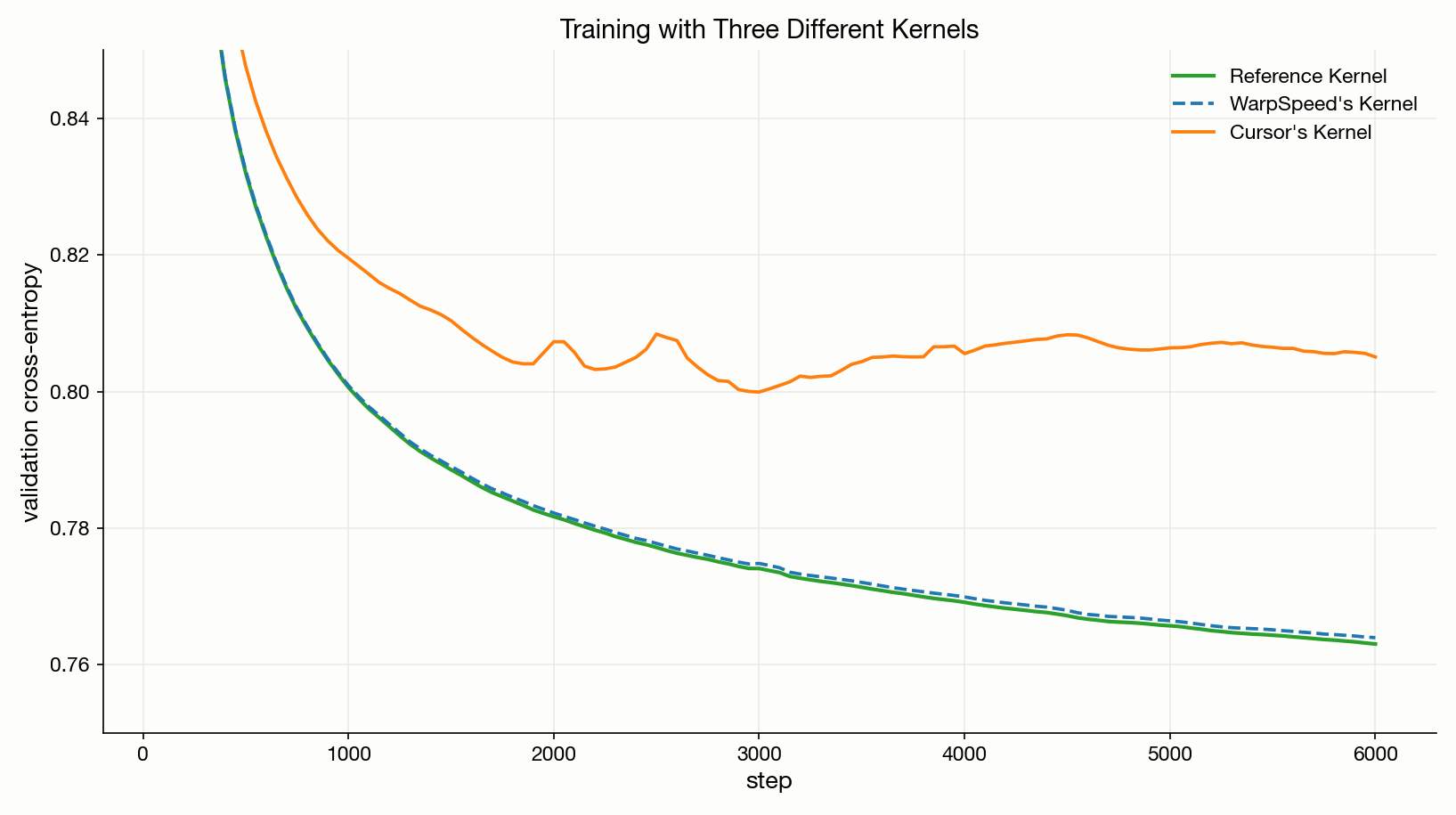
Why did it break?
What one does, in every training step, is sum per-token gradient contributions into the resulting (V, H) embedding-gradient matrix. In this problem, the reference implementation accumulates the per-position gradient contributions in an fp32 scratch buffer, then casts the result to bf16 once at the end. A fast alternative, which is what Cursor's published kernel for this problem does, is to allocate the gradient directly in bf16 and use a packed bf16 atomic-add per contribution. [5]
For a token that occurs exactly once in the input batch, both produce bit-identical output. But what if the token occurs N > 1 times? Then the difference matters: the reference sums in fp32 (one final rounding), while the bf16-accum kernel rounds the running partial sum back to bf16 after every addition. N roundings instead of one. At bf16's ~3 decimal digits of precision, rounding after every add throws away the small increments. The longer the addition chain, the more contributions vanish…
The verifier doesn't catch this. It samples the inputs uniformly at random (u.a.r.) over the vocabulary, so in a batch of ~16K tokens drawn from a vocabulary of 65K, almost no token id appears more than once [6]; the few that do appear two or three times stay within the verifier's 1% tolerance budget, and the kernel passes.
Why is this an issue? Well, natural language is Zipfian, not uniform. The most common token in English text (the) accounts for around 5% of all positions. In a 16K-token batch, it gets touched hundreds of times. Those high-frequency tokens are exactly where the bf16-on-every-add rounding chain accumulates bias, while the reference stays correct.
Easily masked
This bug is tricky. Whether you see it in your training loss depends entirely on configuration choices. As we saw above, the bug is sensitive to the input distribution: it does not appear under the uniform distribution, and does emerge under a Zipfian one. What about other choices? What if, for instance, we swapped SGD for AdamW?
In that case, the bug is masked. The training appears fine, by every metric you'd normally check. All three curves overlap to within step-to-step noise. This is due to Adam's update, which is roughly g / sqrt(E[g²]). If the bug shrinks both the numerator and the denominator by the same multiplicative factor, which is approximately what bf16-on-every-add does, the ratio cancels and Adam takes the same step it would have taken with the correct gradient. In other words, the bias is still there at every step, but the optimiser absorbs it.
A silent lottery
The hardware (and software) lottery reminds us that going off the beaten path costs you speed. But there is a second lottery along that same path, and it is the more insidious one. New ideas require new kernels, and new kernels can be silently wrong. A subtly buggy kernel doesn't just slow a new research idea down, it may quietly kill it. When such bugs emerge, the outcome looks exactly like the idea didn't work. And because the bug is easily masked by configuration choices, one is left wondering if it is the data, hyperparameters, architecture, or indeed the idea itself, which are to blame.
Catching the bug
For completeness, we also generated a WarpSpeed verifier for this problem. The kind of failure mode we just saw, a kernel that passes one input distribution but corrupts gradients under another, is exactly what WarpSpeed's verification framework is designed to catch. We then let WarpSpeed search against this verifier. The resulting kernel runs between 2× and 10× faster than the reference, and remains accurate across distributions, including Zipfian. Curiously, this problem also marks our widest loss to Cursor's kernel in the benchmark. That gap is by design: it is the cost of accumulating in larger precision and retaining accuracy.
Simple verifiers allow overfitting
One of the most common risks inherent in simplistic verifiers is that of overfitting. The verifiers in the benchmark all exhibit this pattern in multiple forms. Both Cursor's published kernels and our own were generated against these verifiers. For illustrative purposes, we examine Cursor's kernels here — they're publicly available, which makes them convenient case studies. We found that they indeed exploit these verification gaps. The point of what follows is to examine the verifiers, not the kernels.
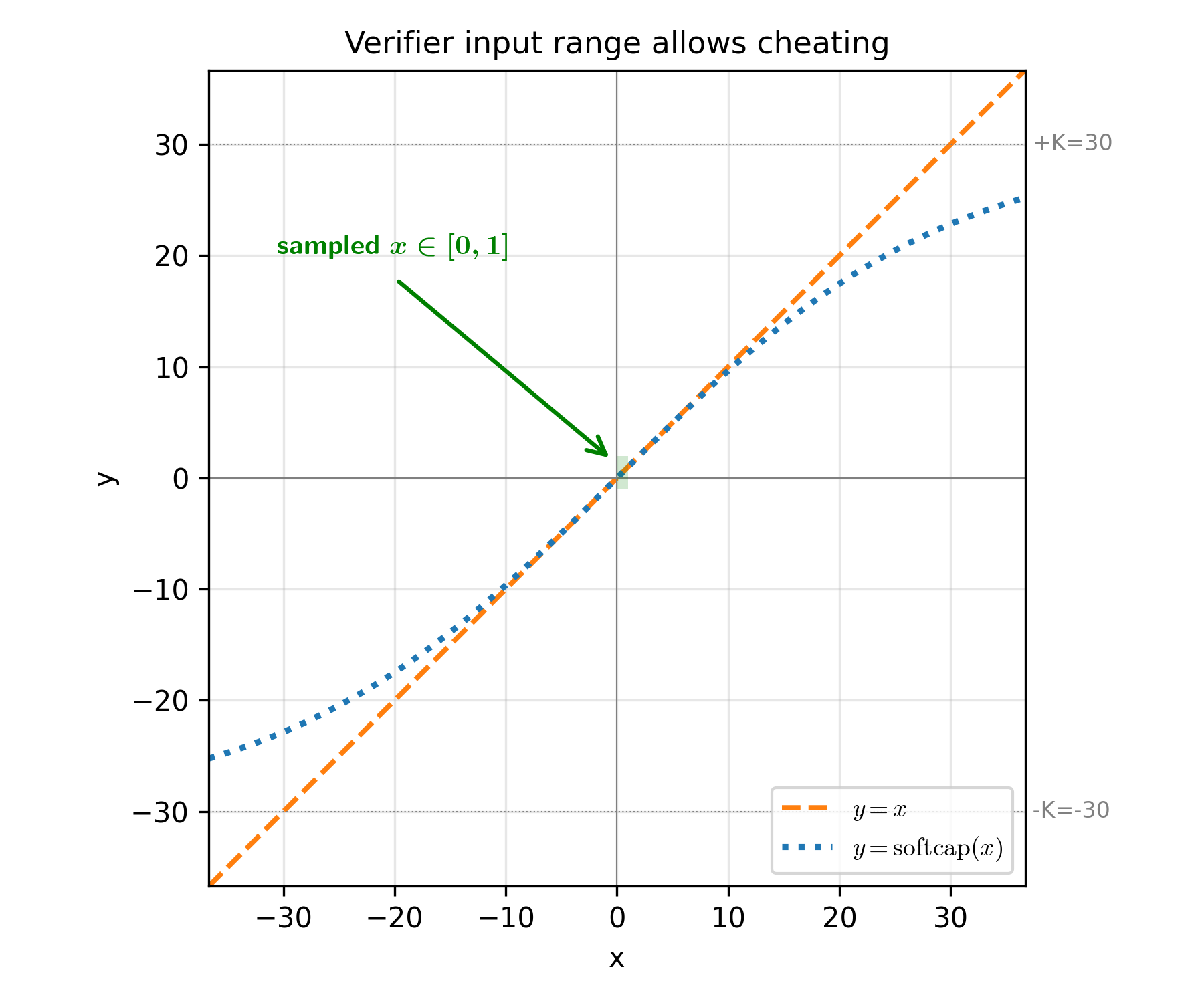
One form is overfitting to the input distribution: the verifier's inputs are sampled from a distribution too narrow to exercise the operation it claims to test. An illustrative problem here is an implementation of Gemma-3's attention softmax, which applies a softcap before the softmax. Softcapping compresses any logit much larger than some value K in magnitude (in this case, K=30) back into the range [-K, K], by passing it through a scaled hyperbolic tangent.
However, the verifier populates the input logits using the softmax of a standard Gaussian. Therefore the input is always bounded between zero and one. Recalling that K is large (30, in this case), and that tanh(z) ≈ z around zero, it therefore holds that K⋅tanh(x/K) ≈ x, and the softcap effectively turns into the identity in the verifier's range! One can simply omit it and still pass the verifier. Of course, this approach breaks once one feeds in logits of larger magnitude.
Another error mode is that of overfitting to seeds. To allow for consistent evaluation, the benchmark's verifiers use a fixed RNG seed. While methodologically sound, there is a tradeoff to be considered: what if one were to generate solutions to each of the problems by running against the benchmark's verifier as a process-reward (in other words, enforcing no train/test split)? Well, in that case, they run the risk of overfitting. We ran this experiment, evaluating each of the published solutions against both the default seed, as well as three freshly chosen ones [7]. Upon this 're-rolling' of the dice, eight of the kernels that had previously passed verification, now failed on one or more of the workloads [8]. We note that seven more solutions failed (by a small margin), even when tested under the default seed [9].
Overfitting to fixed inputs means encoding the verifier's input set directly into the kernel itself. An illustrative problem here computes the RoPE inverse-frequency vector, a short list of numbers determined by a single scalar parameter, theta. The verifier executes the solution across 16 workloads, each with its own value of theta. The overfitted solution contains three dictionaries, each keyed on exactly those 16 thetas, mapping each to the precomputed constants needed to specialise the GPU kernel for that value. At first glance this looks like ordinary precomputation. But there is no fallback: the constants are never computed from theta directly. Invoking the kernel with a 17th theta, outside the precomputed set, crashes outright.
Yet another variant is that of overfitting to shapes. An illustrative problem here fuses a residual addition with RMSNorm over a 2D tensor whose row count, batch_size, varies wildly in production; it is essentially the total token count per request. The verifier executes the solution across seven workloads, each with a different batch. The overfitted solution defines a separate precompiled kernel for each of those seven values, with the size baked in as a compile-time constant. There is no dynamic-shape fallback: any other batch_size, even an adjacent one, aborts at dispatch.
Afterword
Fast kernels are slow work. The hard part isn't making them fast; it's being sure they're right.
At doubleAI, we're building artificial expert intelligence systems: systems meant to push beyond the limits of scarce human expertise. In domains with true reasoning depth, it's not enough to produce something plausible — you need to explore a large solution space, and you need a way to know when you've actually found something correct. That requires a different toolkit than today's mainstream AI: systems that can search deeply, generating genuinely new candidates rather than remixing familiar ones, and then earn trust through verification.