WarpSpeed on Blackwell: A Second Day
After a second day of search, WarpSpeed beats 99% of SOL-ExecBench's Blackwell kernels

WarpSpeed on Blackwell: A Second Day
Last month we gave WarpSpeed one day to run on NVIDIA's SOL-ExecBench: 235 of the hardest CUDA kernels in production AI, drawn from models like DeepSeek, Qwen, and Gemma and scored on a Blackwell B200.
With one day of compute, WarpSpeed beat the optimised PyTorch baselines on 90% of them, running 2.24× faster on average.
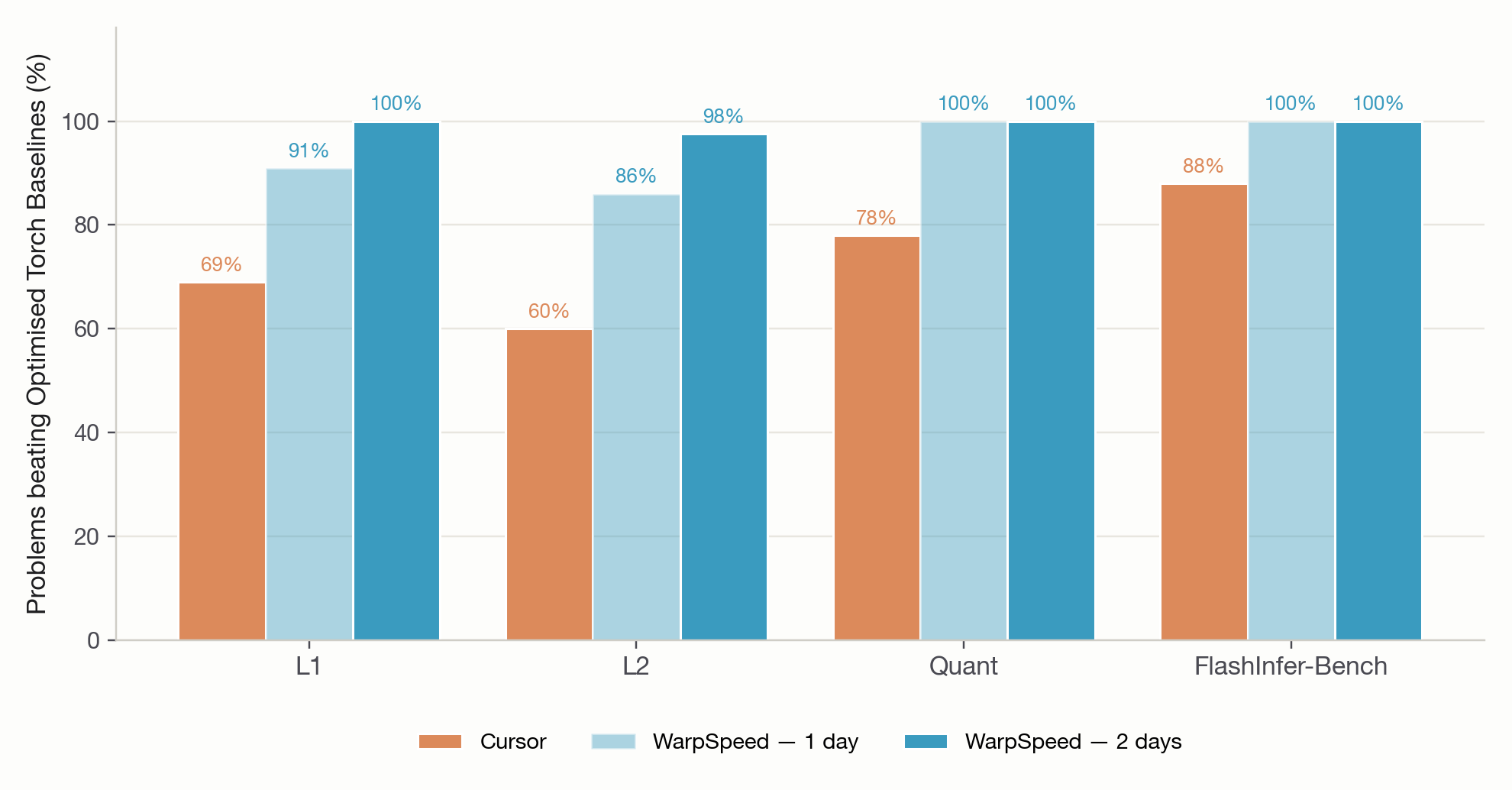
This time, we gave it two days. With a second day of search, WarpSpeed beats the baseline on 99% of the problems — and runs 3.14× faster on average.[1]
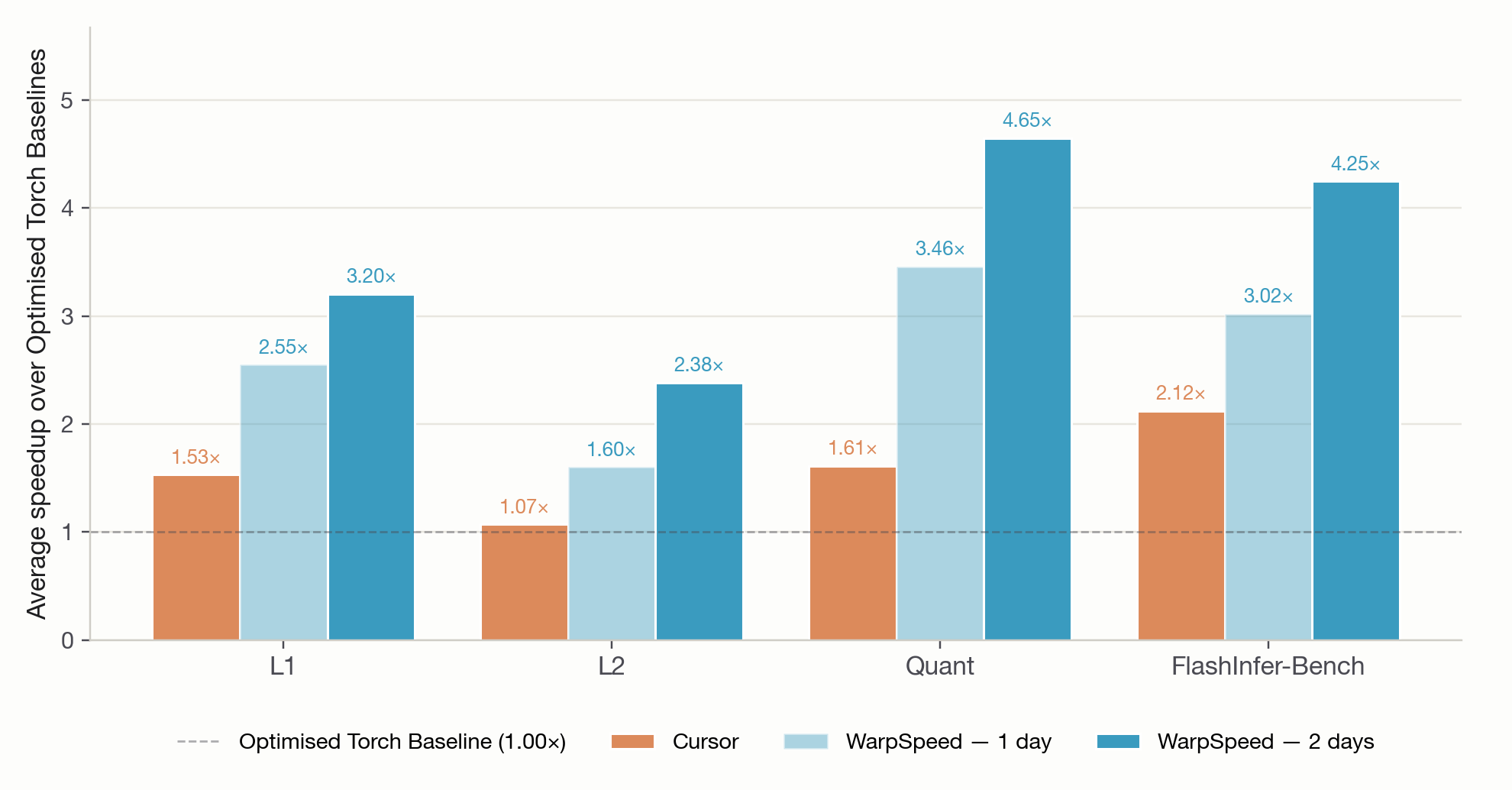
With two days of search, WarpSpeed improved its performance across every single set of problems. Our system is not only in the #1 position in the benchmark, but it is also close to the effective speed of light on many of the produced kernels.

Measured against the optimised PyTorch baselines, nearly every single one of the kernels WarpSpeed produced is faster. And often by a very wide margin.
For the hardest AI workloads on Blackwell, WarpSpeed doesn't just beat Torch — it approaches the physical limits of the underlying hardware.
[1] WarpSpeed beats the baseline on 233 of 235 problems. Average speedup is the geometric mean of per-problem speedup ratios.